Imagine you have a scanned document, a photo of a street sign, or a screenshot of a social media post, and you want to copy the text from it. This is where OCR (Optical Character Recognition) technology comes in. OCR tools, often referred to as image-to-text converters, extract and transform text from images into digital, editable formats. But how does this process actually work? Let’s dive deeper and break it down in an easy-to-follow manner.
Understanding OCR: What Does It Do?
OCR is a system that uses AI (Artificial Intelligence) and advanced algorithms to “read” the text in an image and convert it into machine-readable characters. It does not “see” images the way humans do. Instead, it analyzes patterns, shapes, and pixel arrangements to identify text.
The process involves multiple steps, each designed to improve accuracy and ensure the extracted text resembles the original as closely as possible. Let’s take a closer look at how OCR tools work step by step.
How a Text Extractor Converts Images into Text
An image-to-text extractor goes through the following four steps to extract text from an imput image file. We will first show a diagram showing the steps visually, followed by explanation of each step in detail.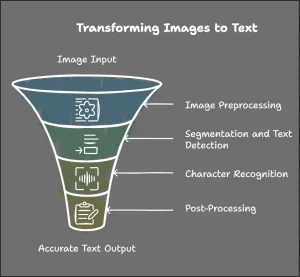
1. Image Preprocessing
Before identifying the text, the image undergoes preprocessing to ensure it is clean and readable for the OCR tool. This phase improves the quality of the image and prepares it for further analysis.
- Noise Reduction: Any distortions, such as random dots or background patterns, are removed. For example, a scanned document might have grainy spots that need to be cleaned up.
- Contrast Adjustment: Low-contrast images (e.g., faint text) are enhanced so that the text stands out more clearly.
- Skew Correction: If the image is tilted, the OCR software aligns the text horizontally to ensure accurate recognition.
- Binarization: The image is converted into a black-and-white format, making it easier to distinguish text from the background.
2. Segmentation and Text Detection
Once the image is processed, the tool identifies the areas containing text. This is done through segmentation, where the image is broken down into smaller parts:
- Lines of Text: The tool detects horizontal lines where text appears.
- Words and Characters: Each word and letter is isolated for individual analysis.
For example, if you upload a page from a book, the OCR software will analyze it line by line, breaking it into smaller components.
3. Character Recognition
Now comes the most important step: recognizing the text. OCR systems use advanced machine learning models trained to identify letters, numbers, and symbols.
- Pattern Matching: The software compares the shapes in the image with a database of characters. For example, it identifies the curve of the letter “C” or the straight lines of “H.”
- Feature Extraction: Instead of matching entire shapes, some tools analyze individual components, like the vertical stroke of “I” or the loop in “P.”
OCR tools can recognize text in multiple languages, and many are trained to handle both printed and handwritten text.
4. Post-Processing and Text Correction
Even after recognizing the text, the OCR system refines its results using post-processing techniques.
- Error Detection: If the tool is unsure about certain characters, it highlights them for review.
- Contextual Corrections: The system uses language models to improve accuracy. For example, if it detects the word “recongnition,” it knows the correct spelling is “recognition.”
The final output is cleaned up and formatted as editable text, ready for use.
How Machine Learning Improves OCR Accuracy
Modern OCR tools rely heavily on machine learning (ML) to improve their capabilities. This technology allows OCR systems to learn and adapt over time, making them smarter and more accurate.
- Training Data: During the training phase, the OCR model is fed thousands of images containing text in various fonts, sizes, and languages. This helps it recognize patterns more effectively.
- Adaptive Learning: Some OCR systems learn from user input. For instance, if you correct a misidentified word, the tool can use that feedback to avoid similar errors in the future.
Machine learning enables OCR tools to handle difficult tasks like recognizing cursive handwriting, stylized fonts, or text in poor-quality images.
Factors That Impact OCR Accuracy
OCR tools are impressive, but their performance can vary depending on several factors. Let’s explore the key elements that influence results:
Image Quality:
High-resolution images produce better results. Blurry or pixelated images make it harder for the OCR tool to distinguish text from the background.- Example: A scanned PDF with 300 DPI (dots per inch) will be more readable than one with 72 DPI.
Text Fonts and Sizes:
Standard fonts like Arial or Times New Roman are easier to recognize. Decorative or script fonts pose a greater challenge.- Example: Text in cursive handwriting may require a more advanced OCR system to interpret correctly.
Lighting and Shadows:
Poor lighting or shadows across the text can introduce noise, reducing the tool’s accuracy.Language and Character Sets:
Some OCR tools are limited to specific languages. Tools with multilingual support are better for recognizing diverse text.Supported Formats:
Most OCR tools support formats like JPEG, PNG, PDF, and TIFF. However, tools that process scanned PDFs or camera-captured images might require advanced features.
Practical Applications of OCR Tools
OCR technology has countless applications across industries. Here are some real-world uses:
- Document Digitization: Businesses use OCR to digitize contracts, invoices, and historical records, making them easier to store and search.
- Education: Students can scan textbook pages and convert them into editable notes.
- Accessibility: OCR tools help visually impaired individuals by converting printed text into audio or Braille.
- Data Entry Automation: Companies save time by extracting information from forms automatically instead of manually typing it in.
For example, a logistics company might use OCR to extract shipping details from scanned labels, speeding up their operations.
Popular OCR Tools You Can Try
If you’re looking to try OCR, here are some popular tools:
- Google Drive OCR: Automatically converts images to text within Google Docs. Read more.
- Adobe Acrobat: Advanced features for editing text in scanned PDFs.
- Tesseract OCR: Open-source and customizable for developers.
- CamScanner: A mobile app that scans and extracts text from photos.
- Picture2Txt: A web-based app that lets you extract text from pictures in seconds without any account or limit of images. Try it Now!
Each of these tools varies in features and accuracy, so choose one based on your needs.
How to Get the Best Results from OCR Tools
To ensure accurate text extraction, follow these tips:
- Use high-resolution images for better clarity.
- Avoid decorative or unusual fonts whenever possible.
- Ensure proper lighting and remove shadows during image capture.
- Choose OCR tools that support the language and format you need.
Conclusion
OCR tools, or image-to-text converters, use a combination of image preprocessing, character recognition, and machine learning to extract text from images. While not perfect, these tools have revolutionized how we handle information, making tasks like digitizing documents or extracting text from photos incredibly easy.
As technology continues to advance, OCR tools are becoming more accurate and versatile, making them indispensable in both personal and professional settings. Whether you’re digitizing your office paperwork or extracting text from a photo on your phone, OCR tools simplify the process and save time.
So the next time you see a scanned document turned into editable text, remember—it’s not magic, but a fascinating blend of AI, math, and computer vision at work.