Представьте, что у вас есть отсканированный документ, фотография дорожного знака или скриншот поста из социальных сетей, и вы хотите скопировать из них текст. Здесь на помощь приходит технология OCR (Оптическое распознавание символов). OCR-инструменты, также известные как конвертеры изображений в текст, извлекают и преобразуют текст из изображений в цифровые, редактируемые форматы. Но как же работает этот процесс? Давайте разберёмся шаг за шагом.
Что такое OCR и что она делает?
OCR — это система, использующая ИИ (искусственный интеллект) и сложные алгоритмы для «чтения» текста на изображении и преобразования его в машинно-читаемые символы. OCR не «видит» изображения так, как это делают люди. Вместо этого она анализирует узоры, формы и расположение пикселей для идентификации текста.
Процесс включает несколько этапов, каждый из которых направлен на повышение точности и обеспечение максимально близкого соответствия извлечённого текста оригиналу. Рассмотрим эти этапы подробнее.
Как текстовый экстрактор преобразует изображения в текст?
Текстовый экстрактор проходит следующие четыре этапа для извлечения текста из изображения. Ниже приводится схема, демонстрирующая эти этапы визуально, а затем — подробное описание каждого из них.
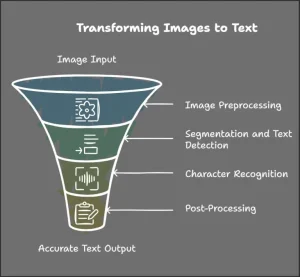
1. Предварительная обработка изображения
Перед идентификацией текста изображение проходит этап предварительной обработки, чтобы сделать его чистым и читаемым для OCR-инструмента. Этот этап улучшает качество изображения и подготавливает его для дальнейшего анализа.
- Снижение шума: Удаляются искажения, такие как случайные точки или фоновые узоры. Например, в отсканированном документе могут быть зернистые пятна, которые нужно очистить.
- Регулировка контраста: Улучшается низкоконтрастное изображение (например, с бледным текстом), чтобы текст выделялся более чётко.
- Коррекция наклона: Если изображение наклонено, OCR-программа выравнивает текст по горизонтали для точного распознавания.
- Бинаризация: Изображение преобразуется в чёрно-белый формат, что облегчает различение текста и фона.
2. Сегментация и обнаружение текста
После обработки изображения инструмент определяет области, содержащие текст. Это осуществляется через сегментацию, где изображение разбивается на меньшие части:
- Строки текста: Инструмент обнаруживает горизонтальные линии с текстом.
- Слова и символы: Каждое слово и буква изолируются для анализа.
Например, если вы загружаете страницу из книги, OCR-программа будет анализировать её строка за строкой, разбивая текст на более мелкие компоненты.
3. Распознавание символов
На этом этапе происходит самое важное — распознавание текста. OCR-системы используют передовые модели машинного обучения, обученные идентифицировать буквы, цифры и символы.
- Сопоставление образцов: Программа сравнивает формы на изображении с базой данных символов. Например, она распознаёт кривую буквы «С» или прямые линии буквы «Н».
- Извлечение особенностей: Вместо сопоставления целых форм некоторые инструменты анализируют отдельные компоненты, такие как вертикальный штрих буквы «I» или петлю буквы «P».
OCR-инструменты могут распознавать текст на нескольких языках, а многие из них поддерживают как печатный, так и рукописный текст.
4. Постобработка и коррекция текста
После распознавания текста OCR-система улучшает результаты с помощью постобработки.
- Обнаружение ошибок: Если инструмент не уверен в некоторых символах, он выделяет их для проверки.
- Контекстные исправления: Система использует языковые модели для повышения точности. Например, если она обнаруживает слово «recongnition», то исправляет его на «recognition».
Итоговый результат очищается и форматируется как редактируемый текст, готовый к использованию.
Как машинное обучение улучшает точность OCR
Современные OCR-инструменты активно используют машинное обучение (ML) для повышения своих возможностей. Эта технология позволяет OCR-системам учиться и адаптироваться со временем, становясь умнее и точнее.
- Данные для обучения: На этапе обучения OCR-модели предоставляют тысячи изображений с текстом различных шрифтов, размеров и языков. Это помогает эффективнее распознавать шаблоны.
- Адаптивное обучение: Некоторые OCR-системы учатся на основе пользовательских исправлений. Например, если вы корректируете неправильно распознанное слово, инструмент использует этот отзыв, чтобы избежать подобных ошибок в будущем.
Машинное обучение позволяет OCR-инструментам справляться с трудными задачами, такими как распознавание курсивного почерка, стилизованных шрифтов или текста на изображениях низкого качества.
Факторы, влияющие на точность OCR
OCR-инструменты впечатляют своими возможностями, но их производительность зависит от нескольких факторов. Рассмотрим ключевые элементы, влияющие на результаты:
Качество изображения:
Изображения с высоким разрешением дают лучшие результаты. Размытые или пикселизированные изображения усложняют задачу различения текста и фона.Пример: Отсканированный PDF с разрешением 300 DPI будет более читаемым, чем файл с 72 DPI.
Шрифты и размеры текста:
Стандартные шрифты, такие как Arial или Times New Roman, легче распознать. Декоративные или рукописные шрифты представляют большую сложность.Освещение и тени:
Плохое освещение или тени на тексте могут создать помехи, снижая точность инструмента.Язык и набор символов:
Некоторые OCR-инструменты ограничены определёнными языками. Инструменты с поддержкой нескольких языков лучше подходят для разнообразного текста.Поддерживаемые форматы:
Большинство OCR-инструментов поддерживают форматы JPEG, PNG, PDF и TIFF. Однако для обработки отсканированных PDF или изображений, снятых камерой, могут потребоваться дополнительные функции.
Практические применения инструментов OCR
Технология OCR имеет множество применений в различных отраслях. Вот несколько реальных примеров:
- Цифровизация документов: Компании используют OCR для оцифровки контрактов, счетов и исторических записей, что облегчает их хранение и поиск.
- Образование: Студенты могут сканировать страницы учебников и преобразовывать их в редактируемые заметки.
- Доступность: Инструменты OCR помогают людям с нарушением зрения, преобразуя печатный текст в аудио или шрифт Брайля.
- Автоматизация ввода данных: Компании экономят время, автоматически извлекая информацию из форм вместо ручного ввода.
Например, логистическая компания может использовать OCR для извлечения данных о доставке со сканированных этикеток, ускоряя свои операции.
Популярные инструменты OCR, которые вы можете попробовать
Если вы хотите попробовать OCR, вот несколько популярных инструментов:
- Google Drive OCR: Автоматически преобразует изображения в текст в Google Docs. Подробнее.
- Adobe Acrobat: Расширенные функции для редактирования текста в сканированных PDF-документах.
- Tesseract OCR: С открытым исходным кодом и настраиваемый для разработчиков.
- CamScanner: Мобильное приложение для сканирования и извлечения текста из фотографий.
- Picture2Txt: Веб-приложение, которое позволяет извлекать текст из изображений за считанные секунды без необходимости регистрации или ограничения количества изображений. извлечь русский текст из изображения
Каждый из этих инструментов имеет свои особенности и точность, поэтому выбирайте тот, который соответствует вашим потребностям.
Как добиться лучших результатов с помощью инструментов OCR
Чтобы обеспечить точное извлечение текста, следуйте этим советам:
- Используйте изображения высокого разрешения для лучшей четкости.
- По возможности избегайте декоративных или необычных шрифтов.
- Убедитесь в правильном освещении и устраните тени при захвате изображения.
- Выбирайте инструменты OCR, которые поддерживают нужный язык и формат.
Заключение
Инструменты OCR, или преобразователи изображений в текст, используют сочетание предварительной обработки изображений, распознавания символов и машинного обучения для извлечения текста из изображений. Хотя они не идеальны, эти инструменты произвели революцию в работе с информацией, делая задачи, такие как оцифровка документов или извлечение текста из фотографий, невероятно простыми.
С развитием технологий инструменты OCR становятся все точнее и универсальнее, что делает их незаменимыми как в личных, так и в профессиональных целях. Независимо от того, оцифруете ли вы офисные документы или извлекаете текст с фотографии на телефоне, инструменты OCR упрощают процесс и экономят время.
Так что в следующий раз, когда вы увидите, как сканированный документ превращается в редактируемый текст, помните — это не магия, а увлекательное сочетание ИИ, математики и компьютерного зрения в действии.