Imaginez que vous avez un document scanné, une photo d’un panneau de signalisation ou une capture d’écran d’un post sur les réseaux sociaux, et que vous souhaitez en copier le texte. C’est là que la technologie OCR (Reconnaissance Optique de Caractères) entre en jeu. Les outils OCR, souvent appelés convertisseurs d’images en texte, extraient et transforment le texte des images en formats numériques éditables. Mais comment ce processus fonctionne-t-il réellement ? Plongeons plus profondément et décomposons-le de manière simple.
Comprendre l’OCR : Que fait-il ?
OCR est un système qui utilise l’intelligence artificielle (IA) et des algorithmes avancés pour « lire » le texte dans une image et le convertir en caractères lisibles par machine. Il ne « voit » pas les images comme les humains. À la place, il analyse les motifs, les formes et les arrangements de pixels pour identifier le texte.
Le processus comprend plusieurs étapes, chacune conçue pour améliorer la précision et garantir que le texte extrait ressemble le plus possible à l’original. Regardons de plus près comment les outils OCR fonctionnent étape par étape.
Comment un extracteur de texte convertit-il les images en texte ?
Un extracteur d’images en texte suit les étapes suivantes pour extraire le texte d’un fichier image donné. Nous commencerons par un diagramme illustrant les étapes, suivi d’une explication détaillée de chacune.
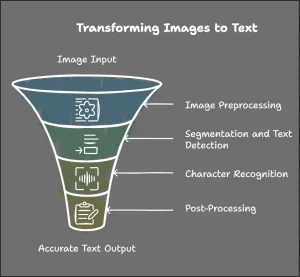
Prétraitement de l’image
Avant d’identifier le texte, l’image subit un prétraitement pour s’assurer qu’elle est propre et lisible pour l’outil OCR. Cette phase améliore la qualité de l’image et la prépare pour une analyse ultérieure.
- Réduction du bruit : Toute distorsion, comme des points aléatoires ou des motifs d’arrière-plan, est supprimée. Par exemple, un document scanné peut avoir des taches granuleuses qui doivent être nettoyées.
- Ajustement du contraste : Les images à faible contraste (par ex. texte pâle) sont améliorées pour que le texte soit plus clair.
- Correction de l’inclinaison : Si l’image est inclinée, le logiciel OCR aligne le texte horizontalement pour assurer une reconnaissance précise.
- Binarisation : L’image est convertie en format noir et blanc, ce qui facilite la distinction du texte de l’arrière-plan.
Segmentation et détection de texte
Une fois l’image traitée, l’outil identifie les zones contenant du texte. Cela se fait par segmentation, où l’image est divisée en petites parties :
- Lignes de texte : L’outil détecte les lignes horizontales où apparaît le texte.
- Mots et caractères : Chaque mot et lettre est isolé pour une analyse individuelle.
Exemple : Si vous téléchargez une page d’un livre, le logiciel OCR l’analysera ligne par ligne, en la décomposant en éléments plus petits.
Reconnaissance des caractères
C’est maintenant l’étape la plus importante : la reconnaissance du texte. Les systèmes OCR utilisent des modèles d’apprentissage automatique avancés pour identifier lettres, chiffres et symboles.
- Correspondance des motifs : Le logiciel compare les formes dans l’image avec une base de données de caractères. Par exemple, il identifie la courbe de la lettre « C » ou les lignes droites de « H ».
- Extraction des caractéristiques : Certains outils analysent des composants individuels, comme le trait vertical de « I » ou la boucle de « P ».
Les outils OCR peuvent reconnaître du texte dans plusieurs langues, et beaucoup sont entraînés à gérer à la fois du texte imprimé et manuscrit.
Post-traitement et correction du texte
Même après la reconnaissance du texte, le système OCR affine ses résultats grâce à des techniques de post-traitement.
- Détection des erreurs : Si l’outil a des doutes sur certains caractères, il les met en évidence pour révision.
- Corrections contextuelles : Le système utilise des modèles linguistiques pour améliorer la précision. Par exemple, s’il détecte le mot « recongnition », il sait que l’orthographe correcte est « recognition ».
Le résultat final est nettoyé et formaté comme un texte éditable, prêt à être utilisé.
Comment l’apprentissage automatique améliore-t-il la précision de l’OCR ?
Les outils OCR modernes reposent fortement sur l’apprentissage automatique (ML) pour améliorer leurs capacités. Cette technologie permet aux systèmes OCR d’apprendre et de s’adapter au fil du temps, les rendant plus intelligents et précis.
- Données d’entraînement : Pendant la phase d’entraînement, le modèle OCR est alimenté avec des milliers d’images contenant du texte dans différentes polices, tailles et langues. Cela l’aide à reconnaître les motifs plus efficacement.
- Apprentissage adaptatif : Certains systèmes OCR apprennent des corrections utilisateur. Par exemple, si vous corrigez un mot mal identifié, l’outil peut utiliser ce retour pour éviter des erreurs similaires à l’avenir.
Machine learning permet aux outils OCR de gérer des tâches complexes comme reconnaître l’écriture cursive, les polices stylisées ou le texte dans des images de mauvaise qualité.
Facteurs influençant la précision de l’OCR
Les outils OCR sont impressionnants, mais leurs performances peuvent varier en fonction de plusieurs facteurs. Explorons les éléments clés qui influencent les résultats :
- Qualité de l’image : Les images haute résolution produisent de meilleurs résultats. Les images floues ou pixelisées rendent plus difficile pour l’outil OCR de distinguer le texte de l’arrière-plan.
- Polices et tailles de texte : Les polices standards comme Arial ou Times New Roman sont plus faciles à reconnaître. Les polices décoratives ou manuscrites posent un plus grand défi.
- Éclairage et ombres : Un éclairage insuffisant ou des ombres sur le texte peuvent introduire du bruit, réduisant la précision de l’outil.
- Langue et ensembles de caractères : Certains outils OCR sont limités à des langues spécifiques. Les outils multilingues sont meilleurs pour reconnaître du texte varié.
Applications pratiques des outils OCR
La technologie OCR trouve d’innombrables applications dans divers secteurs. Voici quelques utilisations concrètes :
- Numérisation de documents : Les entreprises utilisent l’OCR pour numériser des contrats, des factures et des archives historiques, facilitant ainsi leur stockage et leur recherche.
- Éducation : Les étudiants peuvent scanner des pages de manuels scolaires et les convertir en notes éditables.
- Accessibilité : Les outils OCR aident les personnes malvoyantes en convertissant le texte imprimé en audio ou en Braille.
- Automatisation de la saisie de données : Les entreprises gagnent du temps en extrayant automatiquement des informations à partir de formulaires, au lieu de les saisir manuellement.
Exemple : Une entreprise de logistique peut utiliser l’OCR pour extraire les détails d’expédition à partir d’étiquettes scannées, accélérant ainsi ses opérations.
Outils OCR populaires à essayer
Si vous souhaitez essayer l’OCR, voici quelques outils populaires :
- OCR de Google Drive : Convertit automatiquement les images en texte dans Google Docs.
- Adobe Acrobat : Fonctionnalités avancées pour éditer le texte dans des PDF scannés.
- Tesseract OCR : Open source et personnalisable pour les développeurs.
- CamScanner : Une application mobile qui scanne et extrait le texte des photos. obtenir Camscanner.
- Picture2Txt : Une application web qui permet d’extraire du texte à partir d’images en quelques secondes, sans compte ni limite d’images. Essayez-le maintenant !
Chacun de ces outils offre des fonctionnalités et une précision variées. Choisissez celui qui correspond le mieux à vos besoins.
Comment obtenir les meilleurs résultats avec les outils OCR
Pour garantir une extraction de texte précise, suivez ces conseils :
- Utilisez des images en haute résolution pour une meilleure clarté.
- Évitez les polices décoratives ou inhabituelles autant que possible.
- Assurez un éclairage adéquat et éliminez les ombres lors de la capture des images.
- Choisissez des outils OCR prenant en charge la langue et le format dont vous avez besoin.
Conclusion
Les outils OCR, ou convertisseurs d’images en texte, utilisent une combinaison de prétraitement d’images, de reconnaissance de caractères et d’apprentissage automatique pour extraire du texte à partir d’images. Bien qu’imparfaits, ces outils ont révolutionné la gestion des informations, rendant des tâches comme la numérisation de documents ou l’extraction de texte à partir de photos incroyablement simples.
À mesure que la technologie progresse, les outils OCR deviennent plus précis et polyvalents, les rendant indispensables dans les contextes personnels et professionnels. Que vous numérisiez des documents de bureau ou extrayiez du texte d’une photo sur votre téléphone, les outils OCR simplifient le processus et font gagner du temps.
Alors, la prochaine fois que vous voyez un document scanné transformé en texte éditable, souvenez-vous : ce n’est pas de la magie, mais un mélange fascinant d’intelligence artificielle, de mathématiques et de vision par ordinateur en action.