Forestil dig, at du har et scannet dokument, et foto af et vejskilt eller et skærmbillede af et opslag på sociale medier, og du ønsker at kopiere teksten fra det. Det er her, OCR-teknologi (Optical Character Recognition) kommer ind i billedet. OCR-værktøjer, ofte kaldet billed-til-tekst-konvertere, udtrækker og omdanner tekst fra billeder til digitale, redigerbare formater. Men hvordan fungerer denne proces egentlig? Lad os dykke ned i detaljerne og forklare det trin for trin.
Forståelse af OCR: Hvad gør det?
OCR er et system, der bruger AI (kunstig intelligens) og avancerede algoritmer til at “læse” teksten i et billede og omdanne den til maskinlæsbare tegn. Det “ser” ikke billeder på samme måde som mennesker, men analyserer i stedet mønstre, former og pixelarrangementer for at identificere tekst.
Processen indebærer flere trin, som hver især er designet til at forbedre nøjagtigheden og sikre, at den udtrukne tekst ligner originalen så meget som muligt. Lad os tage et nærmere kig på, hvordan OCR-værktøjer fungerer trin for trin.
Hvordan en tekstekstraktor konverterer billeder til tekst
En billed-til-tekst-ekstraktor går gennem følgende fire trin for at udtrække tekst fra en inputbilledfil. Vi vil først vise et diagram, der illustrerer trinnene visuelt, efterfulgt af en detaljeret forklaring af hvert trin.
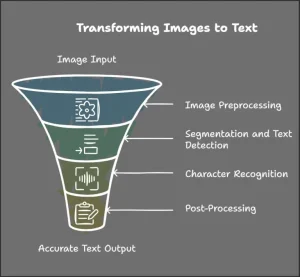
Billedforbehandling
Før teksten identificeres, gennemgår billedet forbehandling for at sikre, at det er klart og læsbart for OCR-værktøjet. Denne fase forbedrer billedkvaliteten og forbereder det til videre analyse.
- Støjreduktion: Eventuelle forstyrrelser, som tilfældige prikker eller baggrundsmønstre, fjernes. For eksempel kan et scannet dokument have kornede pletter, der skal renses op.
- Kontrastjustering: Billeder med lav kontrast (f.eks. svag tekst) forbedres, så teksten fremstår tydeligere.
- Skævhedskorrektion: Hvis billedet er skævt, justerer OCR-softwaren teksten, så den er horisontal for at sikre præcis genkendelse.
- Binarisering: Billedet konverteres til sort-hvid format, så det er lettere at skelne tekst fra baggrunden.
Segmentering og tekstregistrering
Når billedet er blevet behandlet, identificerer værktøjet områder, der indeholder tekst. Dette gøres gennem segmentering, hvor billedet opdeles i mindre dele:
- Tekstlinjer: Værktøjet registrerer horisontale linjer, hvor teksten forekommer.
- Ord og tegn: Hvert ord og bogstav isoleres til individuel analyse.
For eksempel, hvis du uploader en side fra en bog, analyserer OCR-softwaren den linje for linje og opdeler den i mindre komponenter.
Tegngenkendelse
Dette er det vigtigste trin: genkendelse af teksten. OCR-systemer bruger avancerede maskinlæringsmodeller, der er trænet til at identificere bogstaver, tal og symboler.
- Mønstergenkendelse: Softwaren sammenligner formerne i billedet med en database af tegn. For eksempel identificerer den kurven på bogstavet “C” eller de lige linjer i “H.”
- Funktionsekstraktion: I stedet for at matche hele former analyserer nogle værktøjer individuelle komponenter, som den lodrette streg i “I” eller løkken i “P.”
OCR-værktøjer kan genkende tekst på flere sprog, og mange er trænet til at håndtere både trykt og håndskrevet tekst.
Efterbehandling og tekstkorrektion
Efter teksten er genkendt, forfiner OCR-systemet sine resultater ved hjælp af efterbehandlingsteknikker.
- Fejldetektion: Hvis værktøjet er usikkert omkring bestemte tegn, fremhæver det dem til gennemgang.
- Kontekstuel korrektion: Systemet bruger sproglige modeller til at forbedre nøjagtigheden. For eksempel, hvis det registrerer ordet “recongnition,” ved det, at den korrekte stavning er “recognition.”
Det endelige output renses og formateres som redigerbar tekst, klar til brug.
Hvordan maskinlæring forbedrer OCR’s nøjagtighed
Moderne OCR-værktøjer er stærkt afhængige af maskinlæring (ML) til at forbedre deres kapacitet. Denne teknologi giver OCR-systemer mulighed for at lære og tilpasse sig over tid, hvilket gør dem smartere og mere præcise.
Træningsdata:
Under træningsfasen bliver OCR-modellen fodret med tusindvis af billeder, der indeholder tekst i forskellige skrifttyper, størrelser og sprog. Dette hjælper den med at genkende mønstre mere effektivt.
Adaptiv læring:
Nogle OCR-systemer lærer af brugerinput. Hvis du for eksempel retter et fejlidentificeret ord, kan værktøjet bruge denne feedback til at undgå lignende fejl i fremtiden.
Maskinlæring gør det muligt for OCR-værktøjer at håndtere udfordrende opgaver såsom genkendelse af kursiv håndskrift, stiliserede skrifttyper eller tekst i billeder af dårlig kvalitet.
Faktorer, der påvirker OCR’s nøjagtighed
OCR-værktøjer er imponerende, men deres præstation kan variere afhængigt af flere faktorer. Lad os udforske de vigtigste elementer, der påvirker resultaterne:
Billedkvalitet:
Højopløsningsbilleder giver bedre resultater. Slørede eller pixelerede billeder gør det sværere for OCR-værktøjet at skelne tekst fra baggrunden.
Eksempel: En scannet PDF med 300 DPI (dots per inch) vil være mere læsbar end en med 72 DPI.
Skrifttyper og størrelser:
Standard skrifttyper som Arial eller Times New Roman er nemmere at genkende. Dekorative eller håndskrevne skrifttyper udgør en større udfordring.
Eksempel: Tekst i kursiv håndskrift kan kræve et mere avanceret OCR-system for at tolkes korrekt.
Belysning og skygger:
Dårlig belysning eller skygger over teksten kan introducere støj, hvilket reducerer værktøjets nøjagtighed.
Sprog og tegnsæt:
Nogle OCR-værktøjer er begrænset til specifikke sprog. Værktøjer med flersproget support er bedre til at genkende forskellige tekster.
Understøttede formater:
De fleste OCR-værktøjer understøtter formater som JPEG, PNG, PDF og TIFF. Men værktøjer, der behandler scannede PDF’er eller billeder taget med kameraer, kan kræve avancerede funktioner.
Praktiske anvendelser af OCR-værktøjer
OCR-teknologi har utallige anvendelser på tværs af brancher. Her er nogle eksempler fra den virkelige verden:
Dokumentdigitalisering: Virksomheder bruger OCR til at digitalisere kontrakter, fakturaer og historiske optegnelser, hvilket gør dem lettere at opbevare og søge i.
Uddannelse: Studerende kan scanne sider fra lærebøger og konvertere dem til redigerbare noter.
Tilgængelighed: OCR-værktøjer hjælper synshandicappede ved at konvertere trykt tekst til lyd eller Braille.
Automatisering af dataindtastning: Virksomheder sparer tid ved automatisk at udtrække oplysninger fra formularer i stedet for at indtaste dem manuelt.
Eksempel: Et logistikfirma kan bruge OCR til at udtrække forsendelsesoplysninger fra scannede etiketter og derved fremskynde deres drift.
Populære OCR-værktøjer, du kan prøve
Hvis du vil prøve OCR, er her nogle populære værktøjer:
Google Drive OCR: Konverterer automatisk billeder til tekst i Google Docs. Læs mere.
Adobe Acrobat: Avancerede funktioner til redigering af tekst i scannede PDF’er.
Tesseract OCR: Open source og tilpasselig for udviklere.
CamScanner: En mobilapp, der scanner og udtrækker tekst fra fotos.
Picture2Txt: En webbaseret app, der lader dig udtrække tekst fra billeder på få sekunder uden nogen konto eller grænse for antal billeder. Prøv det nu!
Hvert af disse værktøjer varierer i funktioner og nøjagtighed, så vælg et baseret på dine behov.
Sådan opnår du de bedste resultater med OCR-værktøjer
For at sikre nøjagtig tekstekstraktion kan du følge disse tips:
Brug billeder med høj opløsning for bedre klarhed.
Undgå dekorative eller usædvanlige skrifttyper, når det er muligt.
Sørg for korrekt belysning og fjern skygger under billedoptagelse.
Vælg OCR-værktøjer, der understøtter det sprog og format, du har brug for.
Konklusion
OCR-værktøjer, eller billed-til-tekst-konvertere, bruger en kombination af billedforbehandling, tegngenkendelse og maskinlæring til at udtrække tekst fra billeder. Selvom de ikke er perfekte, har disse værktøjer revolutioneret, hvordan vi håndterer information, og gjort opgaver som digitalisering af dokumenter eller udtrækning af tekst fra fotos utrolig nemme.
Efterhånden som teknologien fortsætter med at udvikle sig, bliver OCR-værktøjer mere præcise og alsidige, hvilket gør dem uundværlige i både personlige og professionelle sammenhænge. Uanset om du digitaliserer dine kontorpapirer eller udtrækker tekst fra et foto på din telefon, gør OCR-værktøjer processen enklere og sparer tid.
Så næste gang du ser et scannet dokument omdannet til redigerbar tekst, husk – det er ikke magi, men en fascinerende blanding af AI, matematik og computer vision i aktion.